
At 10 am on the morning of the launch of CI Debugger, our CTO Matt noticed that the images in our docs were broken. Not a mission-critical fix to make, but on launch day, a mistake we needed to rectify fast.
The fix takes seconds, but anyone that has worked in large engineering teams knows that pushing that fix to production can take much longer, especially when using a traditional merge queue. Each PR will wait in the queue until the PRs ahead of it have been tested and merged. Matt's image PR has zero dependencies on the other commits but would still have to wait its turn.
However, using Trunk Merge allows us to merge critical PRs immediately without interrupting the testing and merging of any other PRs in the repository. Trunk Merge automatically parallelizes your merge queue, so each PR only has to wait on others it touches, not everything currently merging into the repository. Instead of waiting hours or upsetting the workflows of our entire team, Matt could merge the images immediately because they had no dependencies with any other PRs in the queue. Here’s how you can do the same thing.
Merge queues solve an important problem
An important part of keeping your engineering team productive is the Not Rocket Science Rule of Software Engineering: "Automatically maintain a repository of code that always passes all the tests." As the rate of commits to a repository scales, this maintenance becomes increasingly difficult because the likelihood of two PRs introducing logically conflicting code changes
increases. We began experiencing this problem regularly once we had more than ten engineers contributing to one repository. This is a significant problem for large teams; for example, Uber pushes approximately one change per minute to their Go monorepo during working hours.
Merge queues are a tool that can solve this problem. They provide an ordering mechanism to detect conflicts and uphold quality standards in the main branch by testing every PR before merging it.
Not all PRs are created equal
Traditional merge queues can be frustrating for developers because they lack intelligence. In a merge queue, all PRs are treated equally, so testing and merging occur sequentially:
However, not all PRs are created equal. PRs that change the behavior of a foundational library will directly impact most others, while a spelling correction on a docs site likely has no impact on any other PRs.
Unfortunately, traditional merge queues don't take this into account. Regardless of the impact of a PR, it has to wait in line with all the others. This inevitably leads to long merge queues that only get longer over time due to two main factors:
Your test suites grow. As your codebase expands, so do tests. If you’re pushing code every 10 minutes and each PR triggers a new test that takes one minute to run, you'll merge the last PR an hour later at the end of the day.
Your team grows. More team members mean more PRs, which in turn causes the merge queue to grow over time.
The more successful your team becomes, the more pronounced this problem becomes–your queue time grows at O(n
Different teams have built workarounds to improve the efficiency of merge queues. Larger teams like Uber have implemented predictive queuing models to address these challenges. On the other hand, smaller teams usually adopt one of two options:
Batching: Multiple PRs undergo testing and merging as a group. That way, you can run just one test across the batch. In the happy path, this results in a speedup commensurate with the batch size. However, if a failure occurs in that test, the PRs must be unbundled and tested independently, resulting in duplicate testing efforts to identify the cause of the failure.
Parallel testing: PRs are tested individually but concurrently with the PRs ahead in the queue. For example, PR #1 is tested against the main repo, PR #2 is tested against the main repo and PR #1, PR #3 will test against main and PR #1 and PR #2, and so on. However, a problem arises when a test fails, as it cascades to subsequent PRs. If tests fail on PR #1, PRs #2 and #3 also automatically fail.
Batching and parallel testing work well when all is good–but in reality tests can and will fail. When these merge queue optimizations encounter test failures, the situation worsens because tests must be canceled and restarted, resulting in wasted compute time.
While the first iteration of Trunk Merge has helped many engineering teams keep their tests passing and productivity high, there’s an opportunity to make a smarter merge queue that can scale to any size.
What’s needed is the ability to separate PRs according to their dependencies. This allows for prioritizing commits that can proceed without delays and bundling PRs together only when they truly rely on each other.
What you need are express lanes.
Keep your code truckin’
Like taking the express lane on a freeway allows you to bypass traffic congestion, Trunk Merge ensures your code keeps on truckin'.
Trunk Merge creates multiple queues based on the content of each pull request. Trunk Merge analyzes the change when a PR arrives to determine what parts of the code are affected. It then assigns the PR to a queue with similar code. This way, frontend PRs are queued with other frontend PRs, and backend PRs are queued with other backend PRs. Cross-functional code (e.g., interface changes) that affect multiple queues create joins between the queues.
If a PR is unaffected by any code currently in the queues, like docs or website copy, Trunk Merge will create a new queue –an express lane specifically for that code. This allows such PRs to be swiftly tested and deployed.
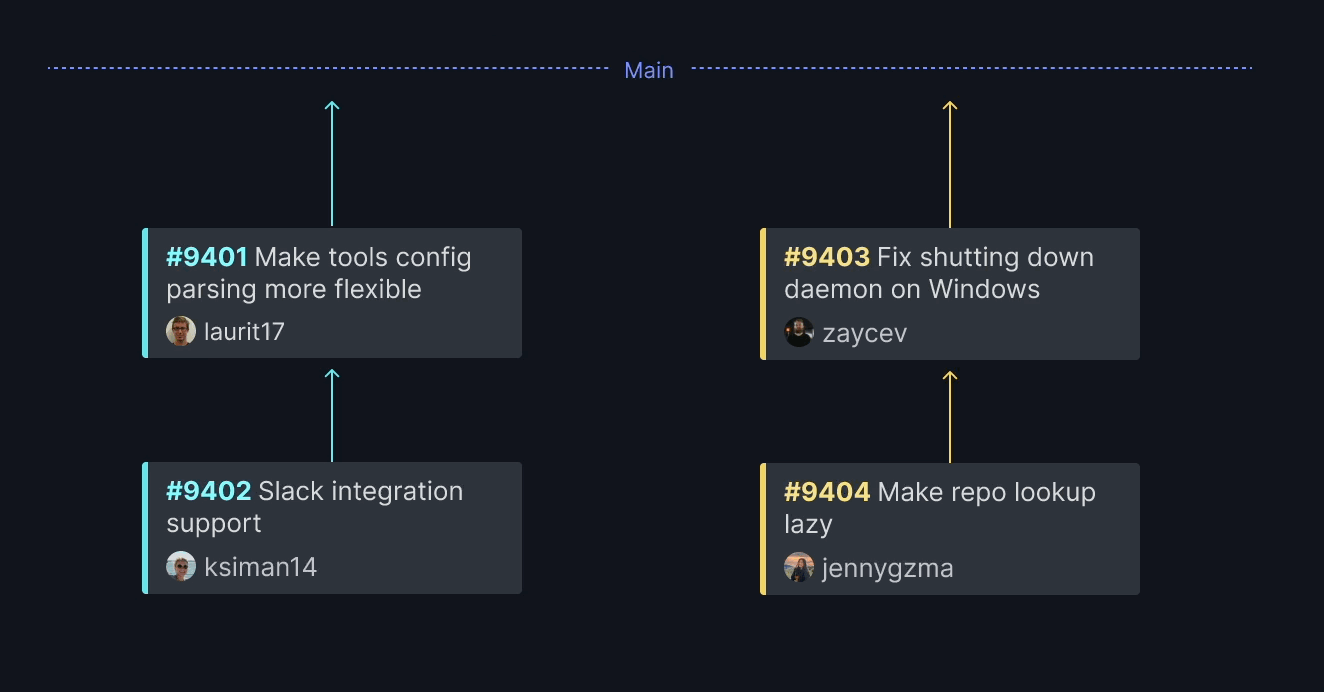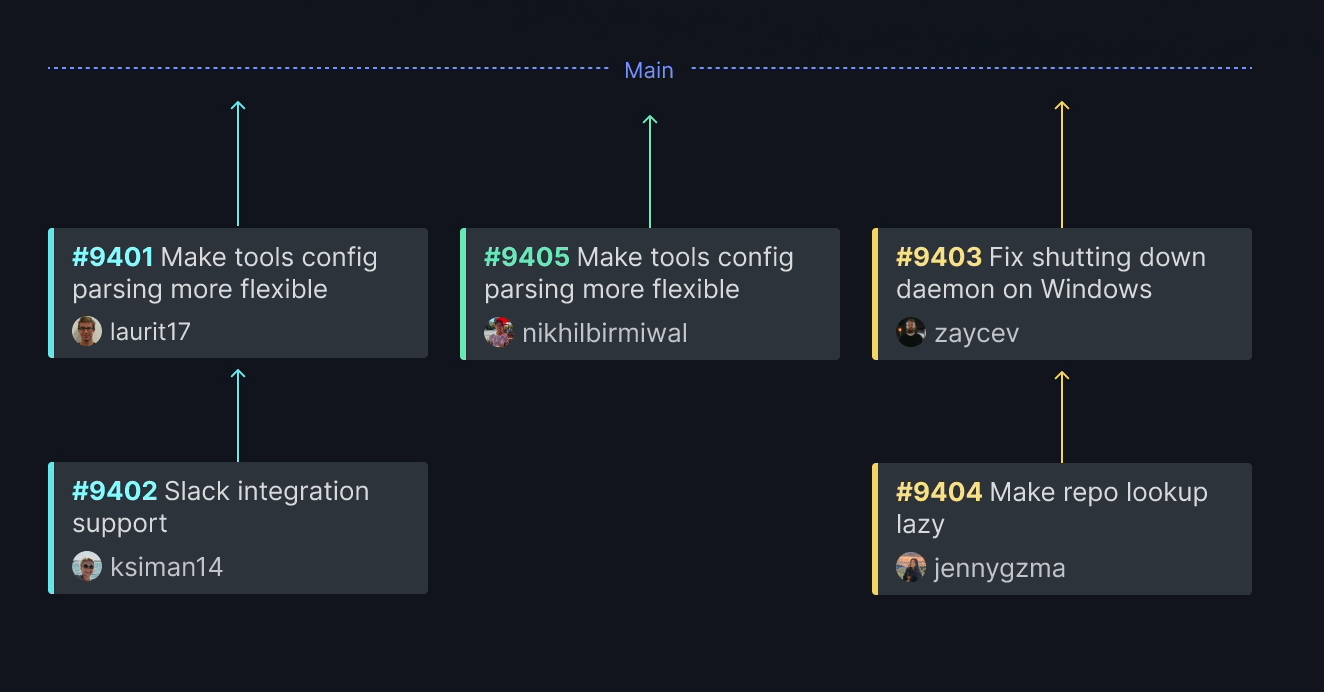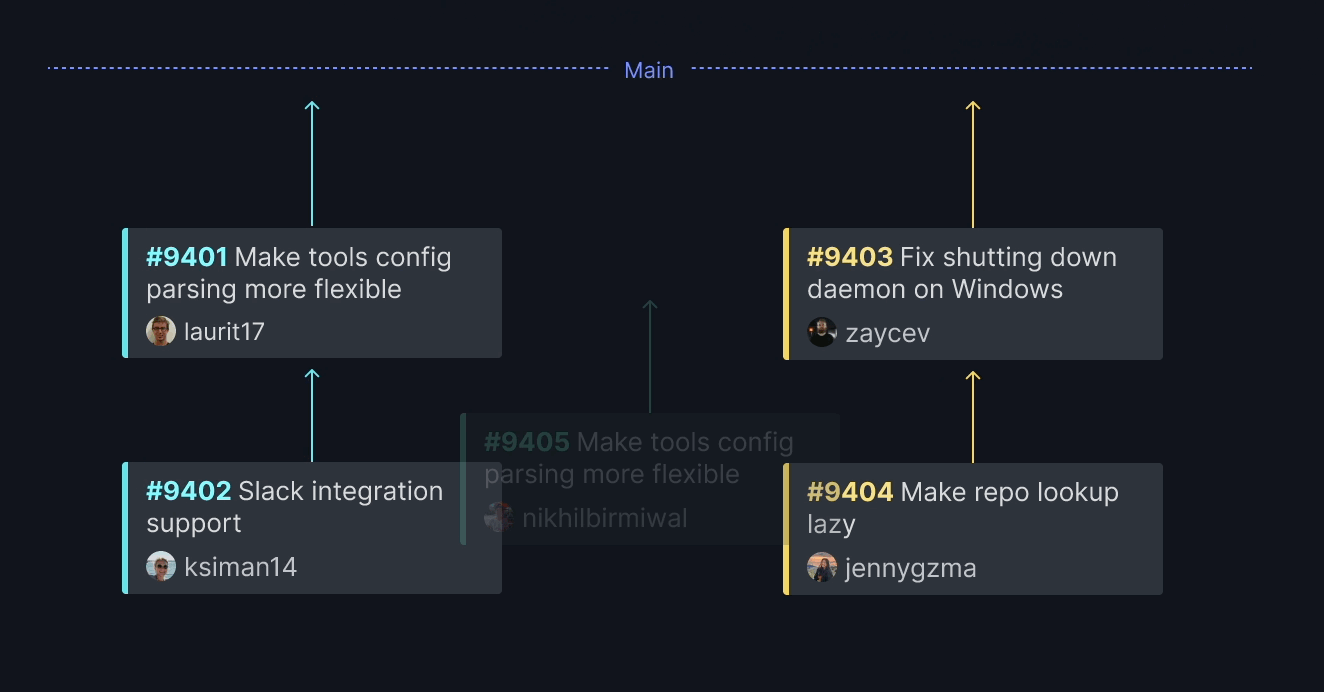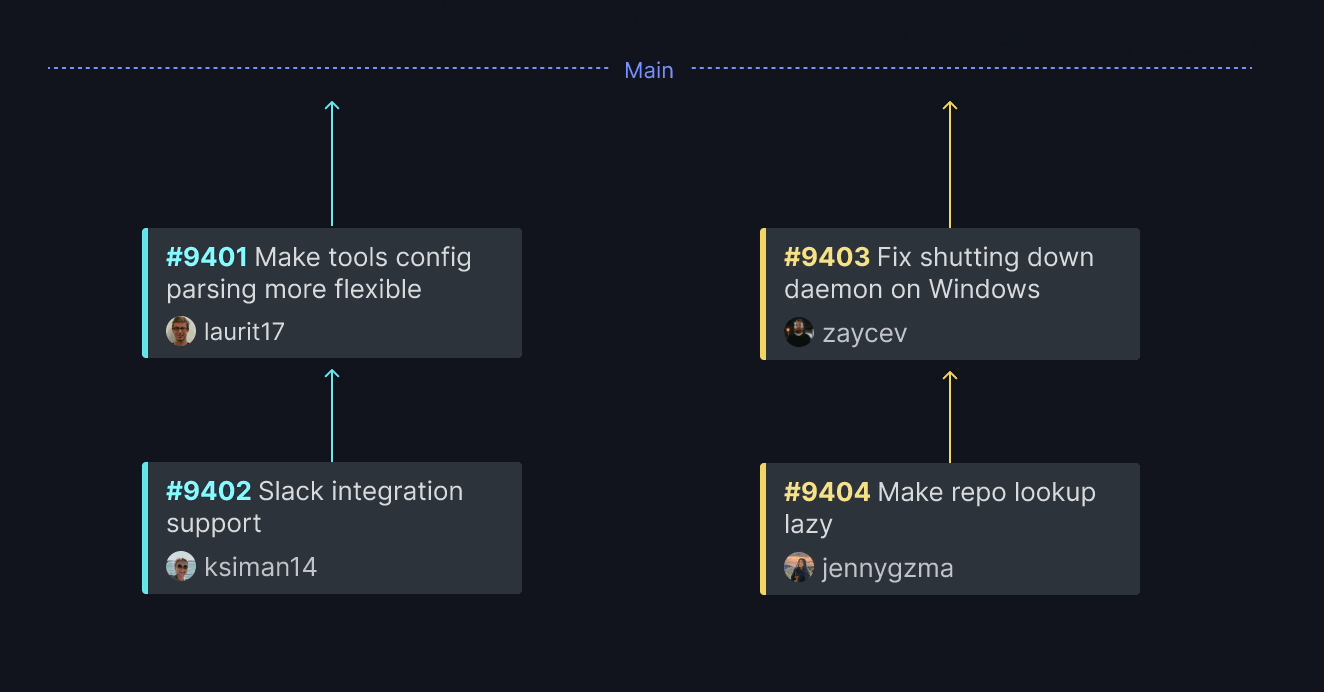
Each of these queues can merge in parallel because Trunk Merge has already analyzed the changes and verified that they do not impact one another.
The limitations of a regular merge queue no longer apply. Trunk Merge scales horizontally, so your team's throughput stays the same as your team scales. Additional lanes will be automatically opened to increase throughput as needed. Your frontend, backend, and infrastructure teams can work independently without needing to create multiple repositories. Small changes with minimal impact, such as updating OpenGraph images can be quickly processed, while significant changes and interconnected code still undergo thorough testing for stability.
Getting Started with Trunk Merge
To start using Trunk Merge, sign up for account today.
Add Trunk Merge to your repository
Set up the jobs for your PRs with your CI provider
Specify the tests you want Trunk Merge to enforce
You can find more information to get started in our Trunk Merge documentation or drop us a line in Slack. Enjoy the express lane!



