This is part two of a blog series about building Trunk Flaky Tests. Part one covered what we’ve learned about the problem space surrounding flaky tests, like how they impact teams, why they’re prevalent, and why they’re so hard to fix. This part focuses on the technical challenges of building a product to detect, quarantine, and eliminate flaky tests.
If you’re curious about what we’ve built, you can find more in the Trunk Flaky Tests Public Beta Announcement blog.
Building a Solution
So far, we’ve only discussed the pain points we’ve discovered while working with our beta customers. To recap, flaky tests are prevalent if you write end-to-end tests, but teams underestimate how many of their tests flake and how much time is wasted dealing with Flaky Tests. Fixing flaky tests can cost more engineering resources than ignoring them, but letting flaky tests accumulate will become debilitating. Finding practical ways to deal with flaky tests is the challenge at hand. Let’s talk about some of the technical challenges we’ve faced in building a solution to this problem.
The Scale of Flaky Tests
In Uber’s Go monorepo, approximately 1,000 out of 600,000 tests were consistently detected as flaky. Dropbox reported running over 35,000 builds and millions of automated tests daily, with flaky tests causing significant operational overhead. At Google, out of 4.2 million tests run on their CI system, about 63,000 (1.5%) had a flaky run over a week. More strikingly, approximately 16% of all their tests exhibit flakiness. Over our private beta, we’ve also identified 2.4K tests that we labeled flaky.
The Challenges That Come With Scale
Production test suites can be huge. They’re run hundreds of times daily on hundreds of PRs, making it challenging to process all that test data to detect flaky tests. Over our private beta, we processed 20.2 million uploads. This means we received 20.2 million uploads of test results from different CI workflows. Each upload can contain the results of one or many test suites worth of results.
Even with a limited number of private beta customers, Flaky Tests processes 40 times more data than all of Trunk’s other product offerings combined. We see thousands of times more data for specific types of tables in our database. The volume of data is a challenge in its own right and difficult to query. Creating summary metrics for each test and overall summary metrics across thousands of runs of tens of thousands of tests is very time-consuming.

Single uploads could contain thousands of tests from a CI job. This data needs to be processed, transformed, and labeled to be displayed on various parts of the Flaky Test dashboard. For example, individual test runs need to have their failure reason summarized by an LLM to be displayed in the test details tab. They also need to be labeled with the correct status, such as if they’re healthy, broken, flaky, and if they’ve been rerun on the same PR.
The practical implication is that we can’t naively query and process the data at the time of request because it would take minutes, which is unacceptable. The metrics need to be precomputed in a timely manner. No one wants to wait more than a few minutes for a summary of a PR.

It’s also not trivial to precompute and cache metrics. Different metrics take a different amount of time to compute. If one metric updates faster than another, you’ll see conflicting numbers on different pieces of UI, which is unacceptable. It turns out that extracting useful metrics from a bunch of test runs and providing them quickly enough to be useful is already a challenge.
Displaying Tests Results
Another interesting challenge is displaying the thousands of tests, their results, their health status, whether they have an attached ticket/issue, and whether they’ve been quarantined. A lot of information needs to be displayed differently if you’re a team lead keeping track of overall test health or a contributor debugging flaky tests on a PR. After revisions with our beta partners, we landed on three key views for different workflows.
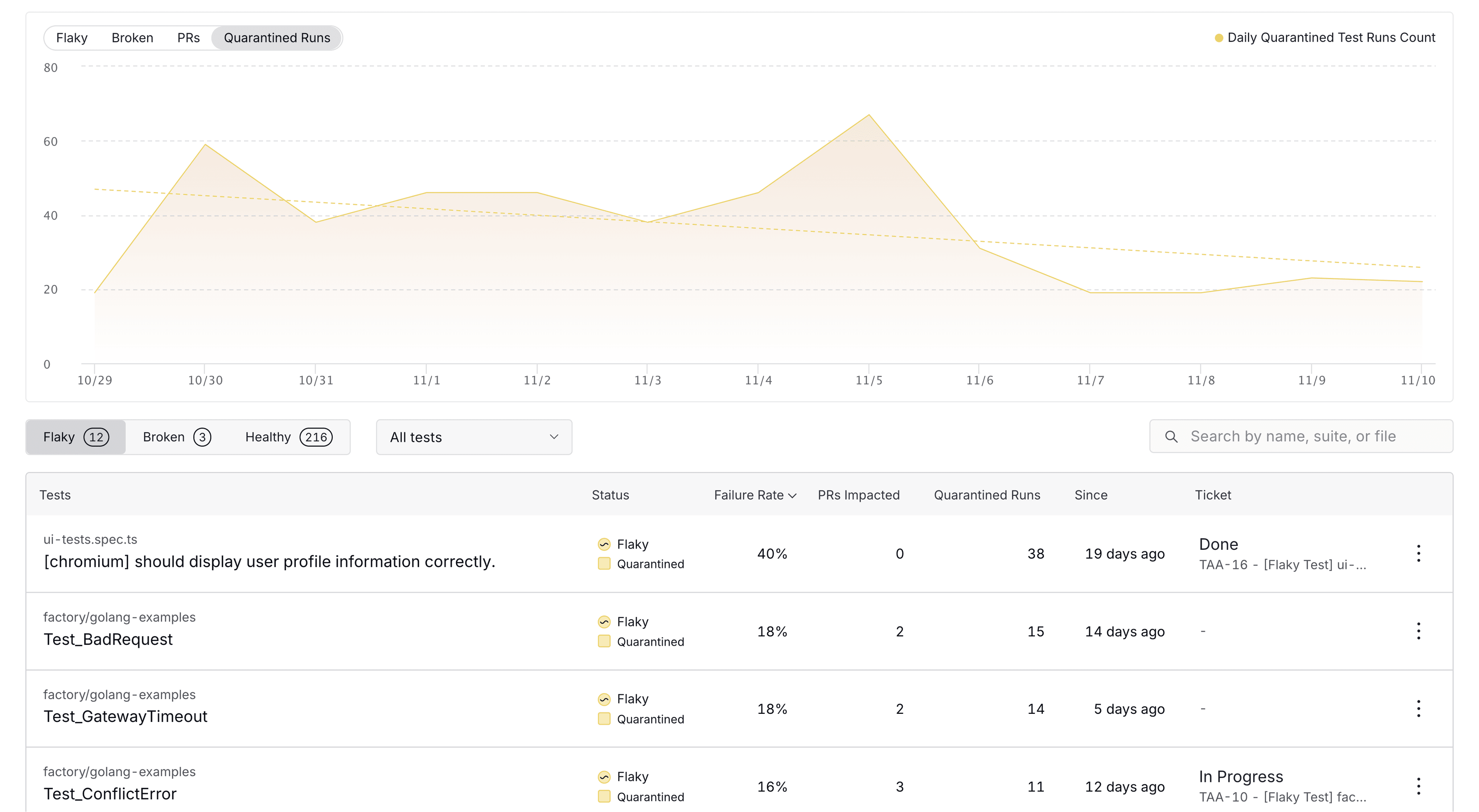
The first screen is the overview dashboard, which shows the overall health of your tests across many CI jobs. You’ll see how many tests are flaky and broken, and you’ll see time-series data on the trends in your repo. This view focuses on helping you understand the overall impact of flaky tests on your repo and finding the highest-impact tests to tackle next.

When you click on a single flaky test, it opens another screen that focuses on helping you debug an individual test. You’ll see a report of its results over the last seven days and the unique ways that the test has failed. You can see when the test started failing and on which branches. This helps you understand what might have caused the test to become flaky and how it fails when it’s flaky, and ultimately helps you debug the test.
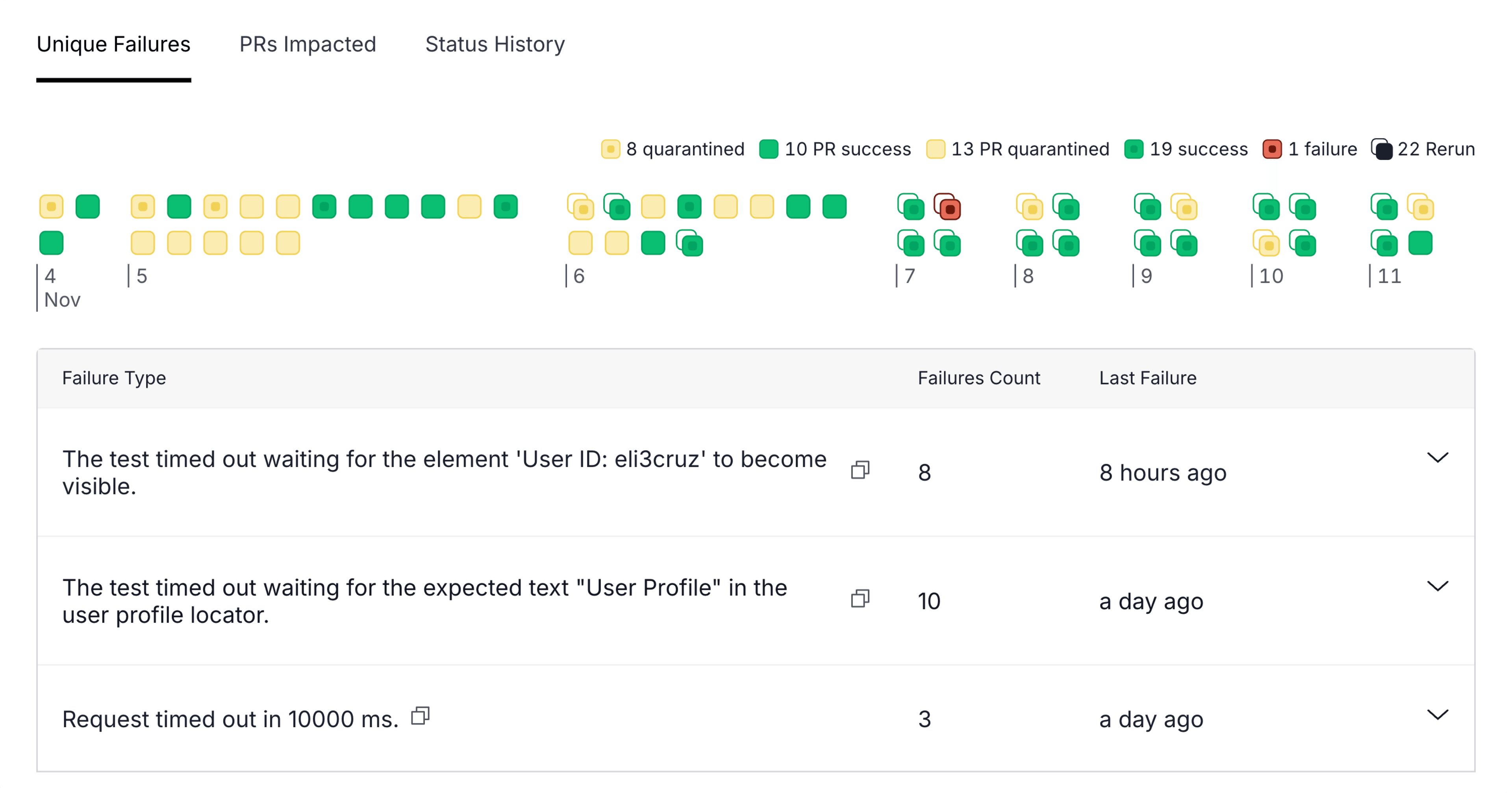
On this same screen, you can click through the stack trace of different test runs with a similar failure reason to help debug flaky tests.
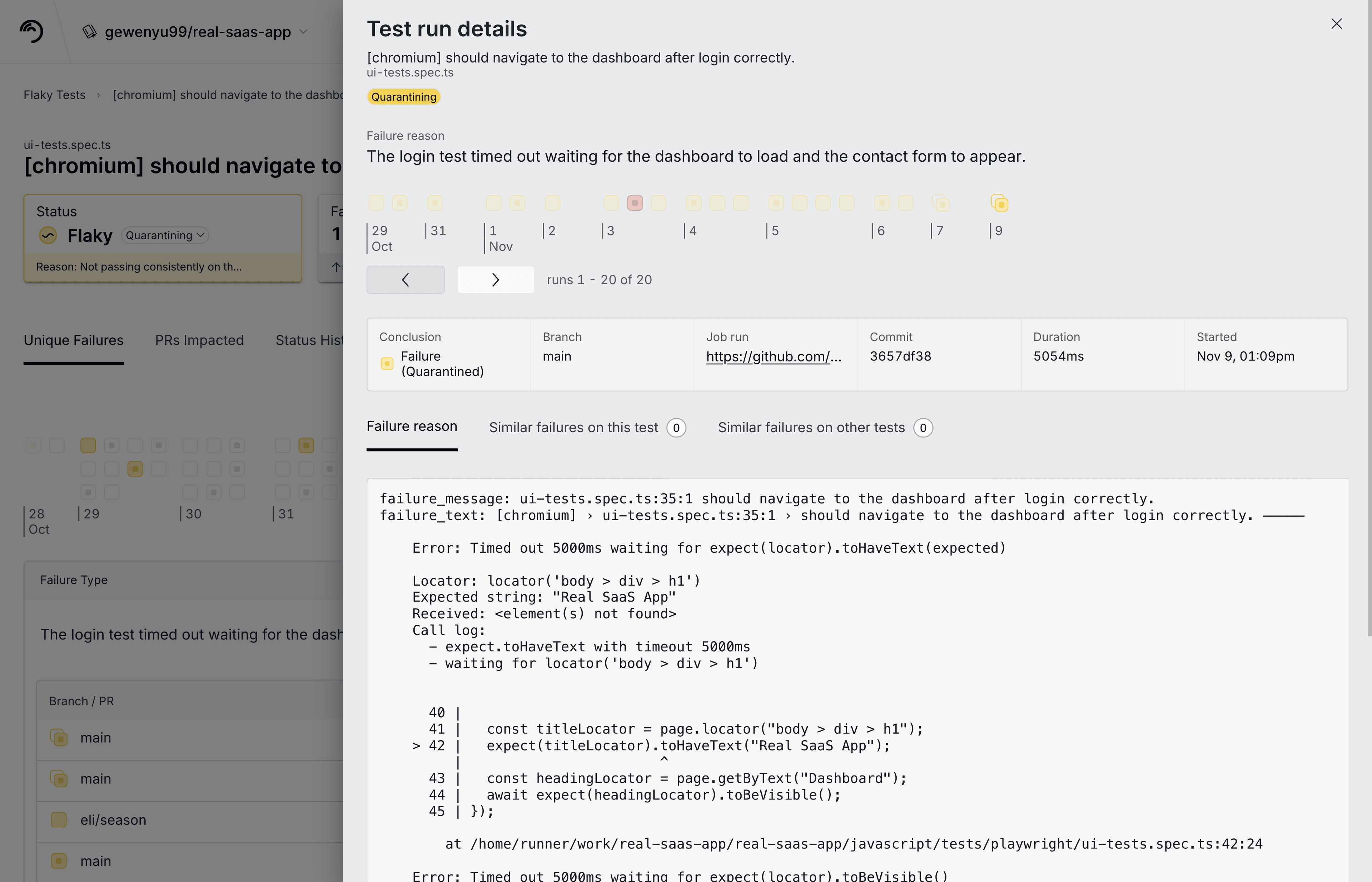
The third screen is a PR Test Summary, which shows an aggregated report for all test results from a single PR. This screen slices the data differently so engineers working on a single PR can quickly scan through failures and verify the results. This screen shows if a test failure is a known flaky test, a known broken test, if it’s quarantined, or if this PR introduces the failure. This helps engineers quickly identify the failures they need to address.

These screens don’t come from the requirements or feedback of a single customer, everyone has a different set of information that they intuitively believe to be important. Through the beta program, by pooling common feedback from different customers, we think these three different screens manage to condense the massive amount of information needed to understand flaky tests into a digestible format. It fits a variety of use cases and scales well even if you’ve got tens of thousands of tests.
Data Quality
There isn’t a single shared standard output format for test results. While most test runners produce JUnit XML, that is still a loose standard. You can't produce high-quality metrics if you don’t get high-quality data uploads.
When we ingested data from our customers, we saw random test names, automatic reruns reported as duplicates or overriding the original results, no test file paths, and all kinds of weird data forms. Handling and sanitizing all of this data is challenging. It felt like a game of constant whack-a-mole: We figure out a way to handle one type of data anomaly and out comes another.
Detecting the inconsistencies and problems in a customer’s uploaded data, prompting them with the proper follow-up steps, and sanitizing the rest is challenging and time-consuming. While we can justify the cost of handling new logic for a new language or test runner, we can’t imagine the pain of building a similar in-house solution, especially if you’ve got a diverse testing stack with legacy code.
Detection Rules
What is a flaky test? It’s a debatable and nuanced topic that begins to feel more like a philosophical question than an engineering one when scrutinized. A test can be non-deterministic in a variety of ways:
How frequently does it have to fail?
Is a timeout failure the same as a DB connection failed failure?
Should a failure on a PR treated the same as on the main branch?
Should the window for detecting a test’s health be N number of runs or a specific time window?
How do we adjust detection for repos that see 10 test runs vs 1000 test runs?
How do we determine if a test is healthy again after a fix?
What about edge cases of tests that fail more than they pass? What about tests that fail once every 1000 runs?
What if tests never run on `main` or another protected branch?
There are many signals to consider when detecting Flaky Tests; the answers here aren’t black and white. While detection can never be perfect and never needs to be perfect, it’s possible to hit a maximum for the vast majority of projects and fine-tune for the outliers. Even during a limited private beta, having access to many diverse technology stacks and millions of test runs gives Trunk Flaky Tests a unique advantage to refine our algorithm continuously.
The private beta customers already helped us find a number of edge cases that helped us detect flaky tests more accurately. Our partnership with partners during our private beta and our new public beta program will hopefully allow us to further improve this process.
Quarantining Tests
Quarantining lets you isolate failures for known flaky tests so they don't fail your CI jobs while continuing to run them. Quarantine looks for known flaky tests and determines which tests should be isolated at runtime so you can avoid code changes usually required to disable flaky tests. This is better than disabling tests because it doesn’t require commenting out tests, which will likely never be revisited. After all, disabled tests produce no noise. It also automatically allows for “un-quarantining” tests if we detect that it’s healthy after a fix. The bottom line is that you’re less likely to lose tests when quarantined.
Quarantining isn’t as challenging to implement as it is tedious. To implement quarantining, you first need a detection engine for flaky tests. Then, you need to serve that information through some API that a script can fetch in CI jobs to see if a test is known to be flaky. That script needs to run and collect the results of tests (recall the non-standard output formats), compare these results with the API response, and then override the exit code if all failures are quarantined. It must handle overrides for specific tests that should always be quarantined or never quarantined. And that script must work on whatever platform and environment you choose to run your CI jobs on. Finally, you must communicate what’s quarantined in each CI job and track quarantined test results. None of this is very sophisticated, but getting all the domino pieces to fall into place nicely is hard.
End-to-End UX
How do you manage flaky tests end-to-end? As discussed in Part 1 of this blog, we don’t see a consensus on a workflow online or among our beta partners. So, if a convention doesn’t exist, we must propose one ourselves. Here’s what we build with the help of our closed-beta customers.
What’s Next?
We don’t think flaky tests are a realistic or practical problem for any tooling team to tackle in-house. The problem is nuanced, and there are no conventions for dealing with it effectively. Our private beta customers allowed us to facilitate much-needed discourse around this problem. By having diverse teams and CI setups to test our solutions and pool feedback and ideas, we can help everyone reduce the cost of trial and error when dealing with flaky tests.
We’re opening Trunk Flaky Tests for public beta so you can help us build a more effective solution for all. The sooner we stop suffering in isolation, the sooner we’ll end flaky tests.